Google Research를 비롯한 많은 연구자들이 참여한 Survey논문을 기반으로 아래 자료를 구성했습니다.
Paper [Arxiv] : Advances and Open Problems in Federated Learning, 2019.
Overview of Federated Learning
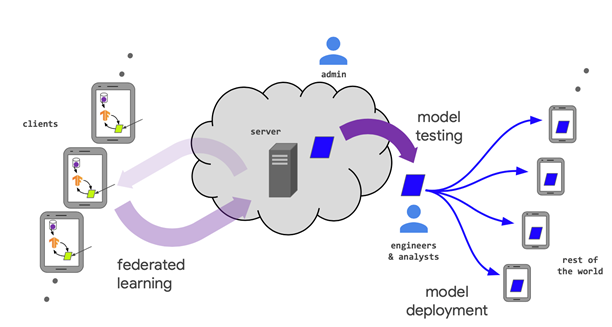
Federated Learning (FL; 연합학습)이란?
- 다양한 entities (clients)가 central server 혹은 그와 유사한 존재의 통제하에 machine learning problem을 협동하여푸는 framework임.
- 하지만, 각 client의 raw data는 local하게 각각의 client에 저장되어 있고, exchange나 transfer가 불가능한 상황임.
- privacy-preservation을 위한 상황이라고 생각하면 됨.
기존 distributed learning (DL; 분산학습)과의 차이
- Distributed learning / Cross-silo federated learning / Cross-device federated learning으로 세분화하여서 비교가 될 수 있음.
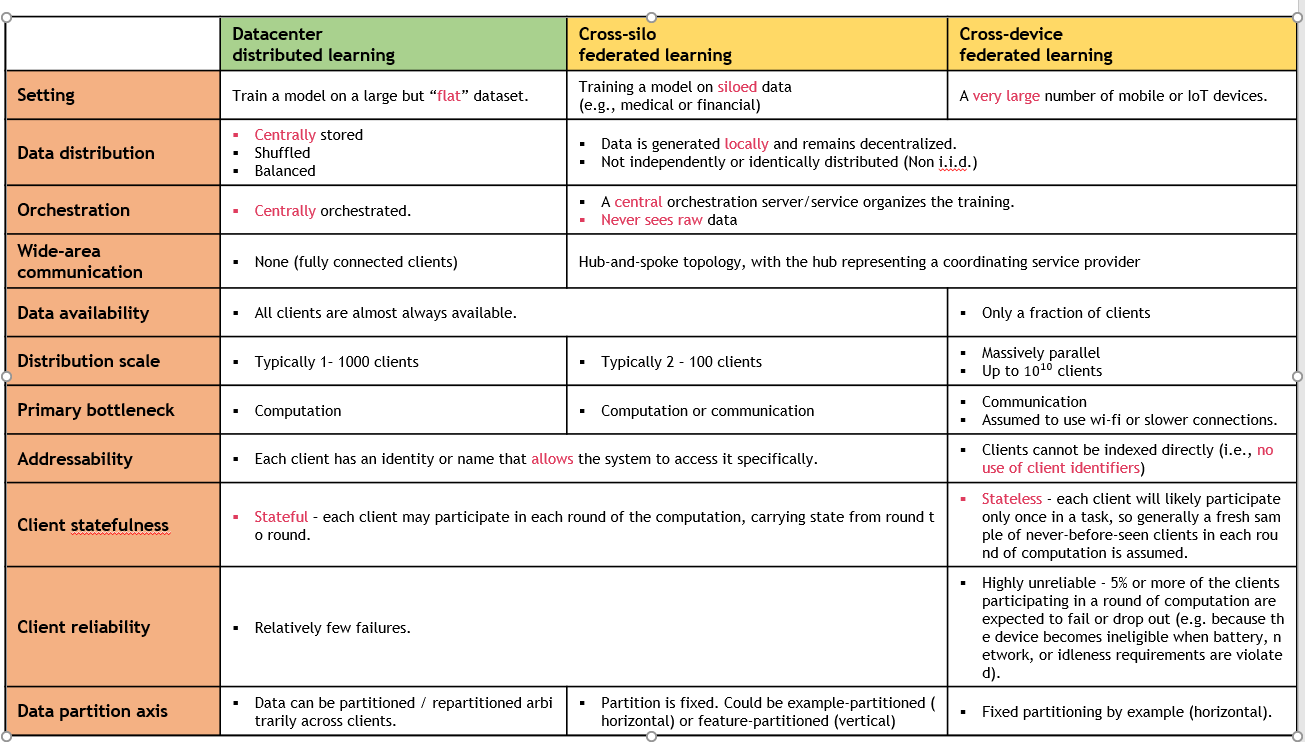
- 표에서는 Setting / Data distribution / Orchestration / Wide-area communication / Data availability / Distribution scale / Primary bottleneck / Addressability / Client Statefulness / Client reliability / Data partition axis 의 분류 항목으로 비교함.
Federated Learning (FL; 연합학습)의 pipeline

- Problem identification: 모델이 FL로 문제로 해결되어야하는지 인지하기.
- Client instrumentation: client에 local data storage 확인.
- Simulation prototyping: prototype model architecture를 proxy model에 대해서 훈련시켜 검증해보기
- Federated model training:여러가지 FL task를 대중적 알고리즘으로 학습시키기.
- Federated model evaluation: standard dataset 혹은 각 클라이언트별 데이터의 성능을 evaluation하여서 체크하기.
- Deployment: manual quality assurance, live A/B testing, a staged rollout 등으로 좋은 성능의 모델 고르기.
Federated Learning (FL; 연합학습) Training Process

- Client selection: Central server에서 학습할 client들 집합(set)을 sampling함.
- Broadcast: 선택된 client들은 server의 weight을 download하고, 대중적 훈련 알고리즘(예: FedAvg)를 적용함.
- Client computation: locally model을 학습시킴.
- Aggregation: 각 client들에서 학습된 update를 합침(Aggregation).
- Model update: 합쳐진 update를 기반으로 central server의 weight를 update함.
*FedAvg 논문: McMahan, Brendan, et al. "Communication-efficient learning of deep networks from decentralized data." Artificial Intelligence and Statistics. PMLR, 2017.
The following file is the original summary of this post written in English.
1_fl_overview.pdf
0.44MB